p.19~20
내셔널리그 투수들은 타서거에 들어서지만, 지명타자가 있는 아메리칸리그 투수들은 타석에 서지 않는다. 연구에 따르면 이러한 시스템의 차이는 아메리칸리그 투수들이 타자 몸 쪽으로 공을 붙이거나 위협구를 던지는 데 있어서 내셔널리그 투수들보다 느끼는 부담감이 적어, 자신 있게 몸 쪽 공을 뿌리는 투수들 때문에 아메리칸리그 타자들이 내셔널리그 타자들에 비해 볼에 더 맞는다고 한다. 가설을 테스트하기 위해 어떤 변수가 필요한가? 타자들이 시즌별로 얼마나 많은 볼에 맞았는지 보여주는 변수 하나만으로 리그별 비교가 가능한가?
그렇지 않다. 타자들의 소속 리그를 구분하는 변수가 있어야만, 몸에 맞는 볼이 어떤 리그의 소속의 선수에게서 발생했는지 구분하고 리그 간 비교를 할 수 있다. 그리고 빅데이터처럼 데이터가 크면 무조건 좋다는 생각으로 메이저리그 데이터가 기록되기 시작한 1871년 관측자료부터 현재까지 쌓인 모든 데이터를 사용할 것인가? 아메리칸리그는 지명타자제도를 1973년부터 채택했기 때문에, 1973년 이전 데이터를 분석에 포함했다면 통계적 결과는 왜곡될 것이다. 부정확한 분석 사태를 미연에 막기 위해 연도 변수를 이용해 빅데이터에서 필요한 부분만을 선별할 줄 알아야 한다. 분석은 간단하지만, 분석에 사용될 데이터를 장만하는 데는 많은 문제 해결능력이 필요하다.
p.26
임의로 선택된 수들의 집합을 임의 변수(Random Variable)라고 부른다. 교수님들이 임의 변수를 습관처럼 반복해서 언급할 때, 복잡하게 생각하지 말고 분석할 때 사용해도 좋은 데이터라는 의미로 받아들이면 된다.
p.26
공격 데이터인 타율이든 투수력 데이터인 방어율이든 선수들의 개별 기록은 다른 선수들의 기록과는 독립적으로 생성되며, 월등히 뛰어나거나 뒤처지는 선수의 기록보다 중간 수준의 성적들이 가장 빈도가 높은 프로야구의 데이터 특성상, 하나의 변수를 가지고 다른 변수를 예측하는 다변량분석에 특히 적합하다.
p.29
타율이나 방어율은 하나 둘 셋 카운트(count)한다기보다는 측정(measure)한다고 말하는 것이 적합하다. 좀 더 가까운 예로 선수들의 몸무게나 키가 있다. 연속 변수는 구체적으로 한 선수의 능력이 다른 선수의 능력과 얼마나 차이가 나는지 정확히 보여준다. 개인적으로는 연구에 사용할 수 있는 연속 변수를 찾아낼 때 희열을 느끼는데, 가장 쉽게 적용할 수 있는 회귀분석은 예측하려는 변수인 종속변수(dependent variable)가 연속형일 때 가장 왜곡 없는 예측결과를 가져다주기 때문이다.
p.31
범주형 데이터가 보기에는 간단해도 통계분석의 결과를 의미있고 현실감있게 해석하는 데 매우 효과적이다. 예를 들어, 홈런과 관중수 증가와의 관계에서 홈런이 많은 팀일수록 해당 팀의 경기를 보기 위해 관중들이 더 많이 경기장을 찾는다는 가설에는 별로 이견이 없다. 하지만 그 홈런의 효과가 아메리칸리그보다 내셔널리그에서 더 크거나 또는 적다는 사실 확인은 구단을 운영하고 마케팅을 담당하는 관계자에게 중요하다. 따라서 리그의 차이를 이분 변수로 표시한다면 각각 다른 리그별 홈런 한 방이 관중을 끌어들이는 효과를 구분할 수 있다.
p.44
분모가 달라지는 이유를 이해하기 쉽게 설명한다면, 표본은 모집단의 부분이며 표본의 분산이 모집단의 분산에 비해 체계적으로 적은 편향(biased)을 보이기 때문에 편향을 보정하는 것이다. 표본에서 나타나는 체계적 편향성을 보정해주도록 표본의 분산을 구할 때 분모에서 표본의 관측값 15명에서 추정하는 모수(여기서는 필라델피아 필리스 팀홈런의 평균)의 개수 1을 뺀 14명을 적용해 표본의 분산을 늘려도 편향되지 않은 모분산의 불편추정량을 구할 수 있다.
p.99
cbind()는 두 대상이 동일한 관측자료를 보유하고 순서가 일치할 때 사용할 수 있는 명령어이기 때문에, 복잡한 데이터를 하나로 연결해야 하는 현실에서 쉽게 사용할 수 있는 명령어는 아니다. 대신 2개의 테이블에 공통 변수가 있을 경우 일을 기준으로 유연하게 합치는 방법이 필요하며, 공통 변수를 기반으로 두 테이블을 묶는 merge() 명령어를 사용해야 한다.
p.106~107
외부에서 가져오는 데이터를 2차 데이터라고 한다. 다른 연구기관에서 만들어놓은 데이터를 자신의 연구에 맞춰 사용하다 보면 직접 모은 데이터가 아니라서 여러 문제점이 발생한다. 그 중에서 처리하기 어려운 부분은 결측값(missing value)이 왜 발생헀는지 파악하고 결측값을 어떻게 처리할 것인가에 대한 결정이다. 결측값이 체계적으로 발생한 것인지 아니면 임의로 발생했는지를 먼저 확인하고, 결측값이 있는 관측값 전체를 버릴 것인지 아니면 대체(imputation)할 수 있는지 결정한다. 결측값 하나 때문에 관측값 전체를 포기할 경우에는 과도한 데이터 손실이 발생해, 살릴 수 있는 관측값의 다른 변수도 포기해야 하는 희생이 따른다.
예를 들면, 야구팀의 성적이 관중 동원에 미치는 영향은 팀과 팬 사이의 친밀도에 따라 결정될 수 있다고 가설했다고 하자. 조절 변수(분석에서 독립 변수와 종속 변수 간의 주요 관계를 변화시키는 변수)로 사용할 팬과의 친밀도 변수가 샌프란시스코 자이언츠팀에서만 결측값이 생겨서 해당 팀 데이터 전체를 지울 경우, 해당 팀의 독립 변수인 야구팀의 성적, 종속 변수인 관중 동원, 그리고 여러 통제 변수로 사용될 데이터들은 살릴 수 있음에도 불구하고 같이 제거되어, 친밀도를 측정하는 조절 변수가 필요하지 않은 다른 모델의 관측량을 낮추는 부정적인 결과가 발생한다. 이러한 사태를 막기 위해 부분적으로 지우는 순차적 제거(pairwise deletion) 방식은 조절 변수를 필요로 하지 않는 모델에서는 샌프란시스코 자이언츠의 관측값을 추가하고 친밀도를 모델에 투입해야 하는 조절모델의 경우에만 샌프란시스코 자이언츠 관측값을 제거하는 방법이다. 참고로 흔하지는 않지만 제거 방법과는 달리 결측값을 대체(imputation)하는 방법도 있다. 결측값이 주변 값들을 활용해 예측값으로 결측값을 대신함으로써 데이터를 버리지 않고 살리는 방법이다. 최근 머신러닝 덕분에 대체 방법이 주목을 받고 있다.
결측값을 갖는 데이터 중에는 결측될 수밖에 없는 특별한 이유가 존재하는 경우가 생각보다 많다. 따라서 결측값을 갖는 관측값의 그룹과 그렇지 않은 그룹 간에 특별한 차이가 있다면, 이유를 확인하지 않고 대체값을 투입하거나 결측값이 있는 케이스를 제거한다면, 최종 통계 결과는 왜곡될 수 있다. 분석에서 대체를 했거나 제거를 했다면, 결측이 체계적으로 발생한 것이 아니라 임의적으로 발생했다는 타당한 이유가 있어야 한다.
p.107
library(Lahman)
View(Master)
라고 책에 적혀 있지만, 작동하지 않아서 찾아봤더니
https://github.com/cdalzell/Lahman/commit/4c672d9d029201e78ab9073783624c43ed38c12e
Removed Master table · cdalzell/Lahman@4c672d9
cdalzell committed Apr 5, 2022
github.com
2년 전에 Master Table이라는 이름 대신 People 테이블로 대체되었다고 한다. 아마 Master라는 어감 때문인거 같다.
p.113
과학적 영역에 들어오기 위해 반드시 답해야만 할 질문이 있다. "측정 가능한가?" 키는 자로, 몸무게는 체중계로 간단히 잴 수 있지만, 눈에 보이지 않는 것들을 측정하기란 쉬운 일이 아니다. 선수의 능력은 무엇으로 재는가? 선수의 능력을 측정할 도구는 믿을 만한가? 측정도구가 원래 측정하려는 내용을 측정하는가? 결론적으로 말하면 세상에는 완벽하게 측정할 수 있는 도구는 없지만, 측정도구의 오류는 여러분이 해당 분야를 알고 있는 만큼 줄일 수 있다.
p.115
https://www.espn.com/espn/feature/story/_/id/12331388/the-great-analytics-rankings#!mlb
p.116
다음 질문들은 측정도구의 신뢰도를 이해하는 데 도움이 될 것이다. 비슷한 상황에서 측정된 변수를 반복 적용하면 같은 결과가 나오는가? 예를 들어, <머니볼>에서 나왔던 오클랜드 에슬레틱스의 2001년도 팀의 홈런수가 2002년에도 비슷하게 나오는가? 그래서 2002년도 팀 홈런수를 추정하기 위해 전년도 홈런수를 사용해도 좋은가? 이러한 질문들은 팀 홈런 지표에 대한 신뢰성과 관련이 있다. 그러면 신뢰도가 높은지 낮은지를 평가하는 기준은 무엇인가? 그 답은 일관성이다. 일관성은 테스트할 때마다 반복되는 결과를 의미한다. 같은 지표를 통해 여러 방법으로 측정하거나 같은 지표를 이용해 다른 시점에 측정했음에도 불구하고 측정결과가 동일한 값으로 나타났을 때, 측정된 지표에 대해 신뢰감이 높아진다. 아무리 신뢰도가 높은 지표라고 하더라도 사람을 대상으로 하는 조사방법에서는 관측시기, 관측담당자, 관측방법 등이 달라지면서 측정결괏값이 일치하지 않는 비표본오차(nonsampling error)가 발생한다. 측정값에는 진정한 값을 둘러싸고 체계적으로 잘못 측정하고 있는 편향(bias)과, 측정방식에는 잘못이 없지만 응답자의 반응이 조금씩 다른 비체계적 측정오류인 분산(variance)이 존재하기 마련이다.
측정오류 = 체계적 편향 + 비체계적 분산
p.120~121
예측에는 합리적인 가정이 들어갈 수밖에 없는데, 흥미로운 부분은 2001년도 실점(645)이 2002년도에도 반복될 것이라는 가정이다. 과연 합리적인 가정인가? 실제 실점은 공격력 지표인 득점보다는 변동성이 덜하기 때문에 종종 전년도와 유사한 수준의 팀실점이 발생하는 경향이 있다. 물론 5 선발 투수까지 구성이 크게 바뀌지 않았을 경우에는 연도 간 실점 수준은 더욱 유사해진다. 반면에 팀 선발 타자진들이 바뀌지 않았다고 해도 팀득점은 매년 크게 출렁이는 경향이 있다. 그런 의미에서 오클랜드의 분석보좌 역은 실점이 작년과 동일(645점)할 것이라는 가정을 한 상태에서 포스트시즌 진출에 필요한 득점을 공식에 대입해서 814점으로 예측한 것이다.
영화 <머니볼>은 부자팀이 아니었던 오클랜드 애슬레틱스가 양키스나 다저스가 거액을 주고 스카웃해오는 거물급 선수들에 대해서는 관심을 끊고, 814라는 목표 팀득점에 기여할 수 있음에도 불구하고 기존 스카우트의 관심에 들어오지 않아 저평가된 선수의 능력을 득점과 상관관계가 높은 지표를 개발하고 적용해가는 이야기이며, 성공적이었던 2002 시즌 오클랜드의 분석 메커니즘은 생각보다 오랫동안 회자되고 있다. 814 팀득점이라는 목표 설정이 가능했던 것도 연도별로 변화의 폭이 크지 않아 신뢰성이 높은 수비지표를 예측 공식에 활용한 덕분이다.
p.126
p.126
p.137
변수 간의 관계를 보여주는 상관관계 분석과는 달리 연관성 분석은 변수 안에 있는 개별 관측자료가 여타 관측자료와 어떻게 어울리는지 파악하는 데 주력한다. 포스트시즌이 끝난 후 선수들은 계약에 따라서 같은 팀에 머물거나 새로운 팀을 찾아서 떠난다. 과연 이적시장에서 특정 팀 출신의 선수를 전략적으로 선호하는가라는 질문에 대해 연관성 분석으로 답하려고 한다.
p.140
연관성 테스트에 적용되는 Apriori 알고리즘이 요구하는 연관성 여부의 기준은 통곗값 support와 confidence로 결정된다. support는 해당 아이템(팀)이 선수들 전체 이동에서 차지하고 있는 정도를 나타낸다.
p.141
confidence는 왼편(lhs, left-and side)에 있는 팀에 대비해서 왼편과 오른편 팀 모두에서 활동한 빈도의 비율이다. 해당 비율이 높다는 의미는 NYA와 PHI에서 활동하면 PIT에서 활동할 경향이 높아 이적시장에서 팀 간에 연관성이 있음을 의미한다.
p.147
히스토그램(histogram)은 변수의 분산 정도와 변수에 있는 사건들이 발생하는 빈도 정도를 보여주는 시각화된 자료다. 특정 사건이 얼마나 빈번하게 발생했는지 막대로 표시한 차트이지만, 막대그래프(barchart)와는 다르다. 막대그래프는 각 팀이 시즌별로 만들어낸 홈런의 개수를 팀별로 보여주지만, 히스토그램은 팀과는 상관없이 홈런이라는 사건이 30개의 메이저리그 팀에서 얼마나 자주 발생하는지를 막대의 길이로 보여주기 때문에 개별 팀의 정보는 없다.
p.155~156
인과관계를 파헤치는 것은 학문적으로 큰 의미가 있다. 상관관계가 인과관계가 되기 위해서는 세 가지 요건이 필요한데, 첫 번째 요건으로 반복적 패턴이 발생해야 한다. 야구에서 나이와 장타율의 관계에 있어서 20대 초반부터 중후반까지는 나이가 들면서 장타율이 증가하는 양의 관계를 보이다가, 30대를 거치면서 장타율이 감소하는 포물선 형태가 대부분의 선수에게 나타난다. 반면에 2000년대 초반 메이저리그에서 한 시즌에 60개 이상의 홈런을 터뜨렸던 장타자들의 나이대가 30대 초중반을 넘어섰다는 사실은 인간의 한계를 극복했다는 찬사를 받았지만, 결국 약물의 힘을 빌려 만들어낸 결과라는 사실이 밝혀지면서 역시 나이와 홈런의 관계는 포물선의 형태임이 다시 한 번 확인됐다. 따라서 정상적인 인과관계는 반복적으로 관측돼야 한다.
두 번째로 시간적 순서가 확보돼야 한다. 나이를 한 살 먹는 것이 선행되고 장타율이 후속으로 따라야 한다. 원인이 되는 변수가 반드시 시간상으로 선행하고 결과 변수가 후속적으로 발생해야 인과관계로 인정을 받는다.
세 번째는 그럴듯하지만 실제 논리적으로 설명이 되지 않는 관계(non-suspirious association)는 인과관계가 아니다. 예를 들어, 국가의 초콜릿 소비가 높을수록 인구당 노벨상 수상자가 높아진다는 가설을 제시한 실제 논문이 있었다. 초콜릿이 인지 기능을 높이는 역할을 해서 노벨상 수상자 배출 가능성을 높인다는 주장이었으며, 실제로 매우 높은 상관관계가 나타났다. 하지만 인과관게를 입증하기에는 당연히 어려움이 많다. 국민의 인지 기능이 아니라, 초콜릿 회사가 여러 사업활동을 통해 소비를 늘리고 그 판매자금을 노벨상 연구에 기부했을 가능성도 열려 있다. 해당 연구에서 초콜릿 소비가 가장 많고 인구당 노벨상을 가장 많이 배출한 국가가 네슬레가 있는 스위스라고 하니, 오히려 초콜릿이 인지 기능 향상에 공헌했다는 이유보다 더 가능성이 있어 보인다. 물론 해당 논문에서도 인과관계와 상관관계를 구분할 것을 꼬집는다.
p.167~168
잔차(residual)는 추정모델에 독립 변수를 넣고 구한 예측값과 실제 관측값의 차이다. 잔찻값이 크면 클수록 추정된 예측선의 예측능력이 떨어진다. 통계학 초반에 이해하기 어려운 개념인 RSS(Residual Sum of Squares)를 배우게 되는데, 예측선으로 설명되지 못하는 범위의 합이다.
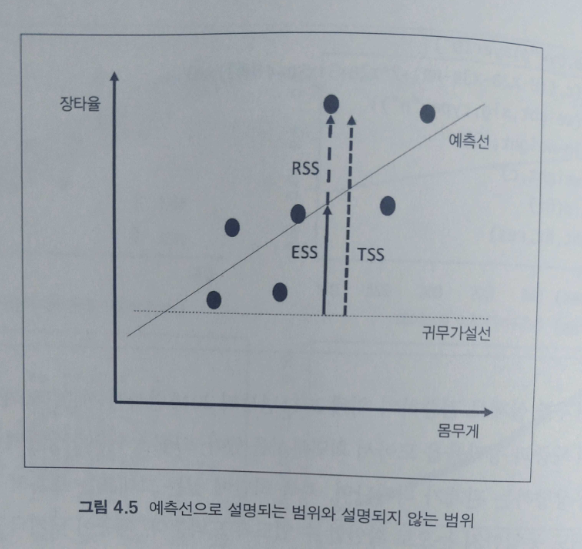
위 그림을 보면, 설명이 되는 부분과 되지 않는 부분의 총합인 전체 자승의 합 (TSS, total sum of squares)에서 설명되는 부분의 합(ESS, explained sum of squares)이 클수록 설명력(R^2)이 증가하게 되지만, 설명되지 않는 부분의 합(RSS, Residual Sum of Squares)이 커지면 설명력이 떨어진다. 설명력이 높을수록 몸무게의 변화가 장타율에 영향을 미칠 것이라는 예측선의 설명되지 않는 범위(RSS)가 적어지므로, 예측선이 주변의 관측점들을 설명할 수 있는 정도가 높아진다.
설명력 R^2 = 1 - (설명되지 않는 부분의 합 / 전체 자승의 합)
세상의 모든 데이터를 수집해서 결론을 내지 않는 한 오류는 존재한다. 요즘처럼 빅데이터가 지배하는 세상에서는 광대한 데이터로 진실에 근접한 패턴들이 밝혀지기 때문에 오류 가능성은 줄어들고 있다. 이러한 산업환경의 변화로 모집단의 특성을 가정하는 추정통계만큼 시장의 변화 트렌드를 보여주는 시각화 기술통계도 산업계에서 큰 주목을 받고 있다. 배우는 데 있어서 기술통계보다 어려운 추정통계를 피하고 싶은 학생들에게는 좋은 소식이 될 수 있겠다. 하지만 여기에도 함정은 있다. 데이터는 지금도 생성되고 있으며 과거의 데이터는 앞으로 생성될 미래 데이터까지 고려한다면 지금의 빅데이터도 여전히 전체의 부분일 뿐이며, 더 큰 함정은 원하는 대부분의 빅데이터는 일반인들의 접근을 허용하지 않는다는 사실이다. 표본을 이용해 모수를 추정하는 추정통계분석은 더욱 현실에 가깝게 발전할 뿐이지 사라지지 않는다. 따라서 오류가 적은 모델을 추정하고 확률이론으로 검증하는 것은 중요한 능력이다.
p.170
참고로, 이항분포의 특별 케이스인 베르누이 분포(Bernoulli distribution)를 기억해둘 필요가 있다. 특별 케이스라고 부르는 이유는 모든 베르누이 분포는 이항분포지만 이항분포라고 해서 베르누이 분포는 아니기 때문인데, 이항 분포가 여러 ㅓ번 시행된 결괏값 집합이라면, 베르누이 분포는 다음 공식처럼 단 한 번의 시도에 대해 성공과 실패 가능성을 제시한다.
발생하지 않을 확률(실패) = p^0 * ( 1- p)^0 = 1 - p
발생할 확률(성공) = p^1 * (1 - p) ^(1- 1) = p
p.172~173
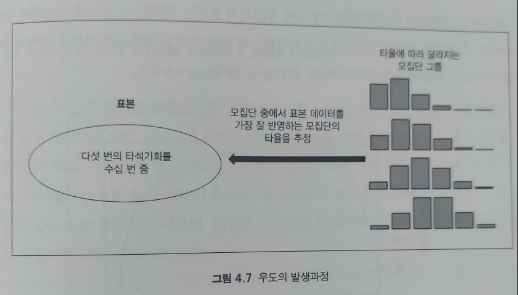
우도의 개념을 이용해 모수를 역추적하는 분석기술은 상당한 관심을 받고 있다. 특정 사건의 발생확률을 최대화할 수 있는 조건들을 데이터를 통해 역추적하고 모수의 특징을 파악해서, 사건의 발생을 예측하고 미연에 방지하도록 도움을 주는 모델 개발이 가능하기 때문이다. 현실에서는 출루율처럼 확률분포를 결정하는 모수를 정확히 알 수 있는 경우가 많지 않지만, 빅데이터를 통해 사건의 발생 여부를 다양하게 시뮬레이션해서 발생할 수 있는 조건을 찾을 수 있다. 톰 크루즈의 영화 <마이너리티 리포트>에서처럼 특정인이 범죄를 저지를 가능성을 극대화하는 조건을 찾아서 범죄 발생 가능성을 예측하고 그에 맞는 대책을 제시해 미연에 방지하는 것이 현실적으로 가능할 수 있는 시점에 이르렀기 때문이다. 다섯 번의 타석에서 두 번의 출루를 할 가능성이 가장 높은 조건인 출루율 모수(parameter)를 찾기 위해 이항확률밀도함수를 역으로 이용하는 방법을 최대우도추정법(Maximum Likelihood Method)이라고 한다. 5장에서 소개할 로지스틱 회귀분석도 최대우도추정법 알고리즘을 활용해 특정 사건 발생 가능성 예측능력이 있는 변수들을 파악한다.
보토 선수의 출루율이 알려져 있지 않은 경우, 그가 다섯 번의 타석에서 두 번 출루하는 것을 옆에서 지켜보고, 앞으로도 다섯 번의 타석에서 두 번 출루할 수 있는 확률을 극대화하는 데 필요한 출루율을 4할이라고 역추적했다면, 4할은 다섯 번의 타석에서 두 번의 출루 확률을 극대화하는 우도(likelihood)가 된다. 확률과의 가장 큰 차이는 확률은 한 사건(다섯 번의 타석에서 두 번 출루)의 조건인 출루율을 알고 있어서 다섯 타석에서 두 번의 출루가 발생할 빈도에 주목할 수 있지만, 모수인 출루율을 모르는 상황에서는 다섯 번의 타석 중에서 두 번의 출루가 발생할 수 있는 빈도가 가장 높게 만드는 조건을 찾아야 하며 그 조건이 우도다.
p.176
이항분포에서 분포의 모양을 정하는 원인은 단 두 가지다. 선수의 출루율과 시행횟수가 확률분포 모양을 정하며, 만약 출루율 3할 선수가 타석에 다섯 번 들어서면 확률분포 모양은 달라질 수밖에 없고, 같은 출루율 4할 타자라고 하더라도 타석에 네 번 들어서는 경우 확률분포는 분명히 달라진다. 이렇게 분포의 모양을 결정하는 요인은 확률분포에서 모수가 되며, 그리스어로 theta(θ)라고 부른다. 보토 선수의 케이스는 출루율이 4할 6푼이고 타석 수를 다섯 번이라고 먼저 밝혔기 때문에 두 가지 모수를 통해 찾아낸 확률분포가 그다지 대단해 보이지는 않지만, 만약 알려진 모수가 없고 동일한 확률분포를 그려낸 데이터가 있을 때 데이터를 통해 역으로 모수를 추정해나가는 일은 분명 흥미로운 작업이다.
최대우도추정법을 통해 다섯 번의 타석에서 두 번 출루할 확률이 가장 높은 선수의 출루율이 4할이라고 밝혔다. 다른 출루율을 갖는 타자들이 다섯 번의 타석에서 출루를 두 번 할 수 있는 확률이 34.6%보다 낮은 것으로 확인되면, 최대우도추정방식으로 모수를 정확하게 추정한 것으로 볼 수 있다. 출루율(OBP)이 2할(0.2)인 선수가 다섯 번의 타석에서 2개의 출루를 할 수 있는 확률은 약 20.48%이고, 3할 선수의 경우는 2개의 출루를 만들어낼 확률이 약 30.87%에 이르며, 전설의 출루율 5할 타자는 31.25%의 확률에 이른다.
p.178
야구 데이터에서 가장 사용 빈도가 높은 타율, 출루율, 장타율 등 연속형 변수들은 데이터 상호 독립성을 띠고 있기 때문에 평균을 중심으로 정규분포를 구성하며, 홈런과 타점 같은 이산 변수의 경우도 변수를 구성하는 데이터 수가 충분할 경우 평균을 중심으로 종 모양으로 퍼지는 정규분포를 띤다고 중심극한정리에 기반해서 말할 수 있다. 중심극한정리가 데이터 분석가들에게 큰 도움이 되는 이유는 홈런과 안타처럼 연속형 변수가 아니라 카운트를 할 수 있는 이산 변수들도 데이터 상호 간에 독립성이 유지되면서, 데이터가 충분히 많을 경우 회귀분석에 사용될 수 있는 이론적 근거를 제공하기 때문이다.
'Growth > 통계' 카테고리의 다른 글
| 파이썬 비즈니스 통계분석 (0) | 2024.02.04 |
|---|---|
| 데이터 스마트 (0) | 2024.02.04 |
| 실전에서 바로 쓰는 시계열 처리와 분석 (0) | 2023.12.09 |
| 데이터 과학을 위한 통계 (1) | 2023.10.21 |
| 사례분석으로 배우는 데이터 시각화 (1) | 2023.10.19 |



댓글