
이제 책을 시작하지만... 서평의 프롤로그를 적을 수밖에 없다. 영원히 고통받는 케네스 로고프 교수... 노벨 경제학상 수상한 하버드 교수인 만큼 두고두고 (역사책에 기록될지도 모르겠다) 고통받으실거 같다.
밑줄긋기
p.14
레인하트와 로고프의 엑셀 조작 실수는 자료분석 환경의 변화에 제대로 적응하지 못한 연구자에게는 항존하는 위험이다. 만약 자료분석이 아래와 같은 루틴에서 벗어나지 않는 연구자라면 누구나 레인하트와 로고프가 범한 실수로부터 자유로울 수 없다고 봐야 한다.
오류 가능성이 높은 자료분석 루틴
1. 인터넷을 검색해서 자료를 다운로드한다.
2. 여러가지 자료를 엑셀 스프레드 시트 형식으로 모두 지정한 뒤 복사 - 붙여넣기로 하나의 시트에 모은다.
3. 엑셀의 함수 기능을 이용하여 자료 전처리를 진행한다.
4. 엑셀의 시각화 기능을 이용하여 시각화를 진행한다.
5. 가공된 자료를 통계 소프트웨어로 불러와서 분석을 진행한다.
6. 엑셀로부터 출력된 그래프와 통계 소프트웨어의 출력 결과를 모아서 문서를 작성한다.
"오류 가능성이 높은 자료분석 루틴"이 자료분석에 미치는 영향은 실로 지대하다. 몇 가지만 예를 들면,
1. 자료 전처리 과정에서 실수가 발생해도 탐지가 어렵고 중간 과정으로 복원이 어렵다.
2. 다른 연구자들이 전처리 과정을 재현할 수 없어서 분석 결과의 타당성에 대한 검토가 어렵다.
3. 엑셀이 제공하는 기본 시각화 문법에만 의존하기 때문에 자료들 간의 복잡한 관계를 시각적으로 확인하기 어렵다.
4. 지리정보 자료, 음성 자료, 이미지 자료, 텍스트 자료, 관계형 자료, 네트워크 자료와 같은 비정형 자료의 처리와 분석이 사실상 불가능하다.
5. 전처리가 끝난 엑셀 자료는 분석 중간에 다른 자료와 병합하는 것이 어려워서 처음 모은 자료에 국한된 연구만 고집하게 된다.
p.22
회귀분석 모형과 회귀분석 모형의 추정을 분명히 구분해야 한다. 전자는 확률이론에 토대를 둔 통계모형이고 후자는 통계적 연산을 통해 모형의 모수를 계산하고 이를 해석하는 방법에 관한 것이다.
p.27
1786년 괴테는 이탈리아 여행기에서 당시를 "통계적 사고에 사로잡힌 시대" (our statistically minded times)라고 불렀다(Hacking 1990, 16에서 재인용). 18세기 말 부터 유럽에서는 질병 발병자나 출생자 수, 사망자 수 등을 기록하는 인구통계자료가 대거 등장하고 있었다. 이러한 인구통계자료를 생성하는 주체는 학자나 민간인들이 아니라 질병을 통제하고 세금 징수 대상이 되는 재산을 정확히 파악하며 징집 대상이 될 성인 남성의 수를 철저하게 확인하고자 한 국가였다. 근대의 국민국가는 통계를 집계하는 주체이며 국민국가의 경계는 통계의 수집 범위와 일치하였고 국민국가의 목표는 통계자료에 의해 설정되고 수정되고 확인되었다. 즉 근대국가의 등장과 통계의 등장은 그 궤를 같이한다고 볼 수 있다. 오늘날 통계라는 단어의 기원으로 간주되는 Statistik을 정초한 것으로 알려지고 있는 프러시아의 Gottingen 학파는 통계란 "국가에 대한 주목할 만한 사실들의 모음"이라고 정의했다(Hacking 1990, 24).
p.35~36
빅데이터와 기계학습과 같은 분석 기술의 혁신으로 소비, 투표, 범죄, 테러 공격, 결혼, 자살 등과 같은 사회현상들이 "설명"되고 "예측"될 수 있을 것이라는 믿음이 확산되는 21세기에 사회과학은 다시 한 번 사회공학과 조우하고 있다. 뉴욕타임스의 영향력 있는 칼럼니스트 데이비드 브룩스는 "데이터의 철학(The Philosophy of Data)"이라는 칼럼에서 다음과 같이 말하고 있다.
만약 독자들이 오늘날 부상하는 철학이 무엇이냐고 묻는다면, 나는 그것을 바로 데이터주의(data-ism)이라고 부르고자 한다. 우리는 지금 엄청난 양의 자료를 모을 수 있는 능력을 가지고 있다. 이 능력은 측정될 수 있는 모든 것은 측정되어야 하며 데이터는 우리의 감정과 이데올로기를 여과해 낼 수 있는 투명하고 믿을 만한 렌즈이며, 미래를 미리 보는 것과 같은 엄청난 것을 할 수 있도록 도와준다는, 어떤 특정한 문화적인 가정을 가지고 있는 것처럼 보인다.
자료와 기술에 대한 낙관적 기대와 찬사가 쏟아지는 21세기 초에, 이 책이 "사회과학 자료분석이란 무엇인가?"라는 다소 원론적이고도 고루한 질문을 던지는 이유는 자료와 기술에 대한 우리의 낙관이 열광-희열-공황으로 이어지지 않도록 하기 위함이다.
p.40~41
원자료만 봐서는 지수적 증가 여부에 대한 정확한 판단이 어렵기 떄문에 양변에 로그를 취해서 확인해 보자. 처음 인구를 y_0이라고 하고 증가율을 r이라고 하면
양변에 로그를 취해 주면,
즉, 시간에 대한 선형 함수로 변하게 된다.
p.49~51
사실 자료를 보지 않더라도, 사회과학의 정치경제적인 관점에서 멜더스 주장의 허구는 쉽게 간파할 수 있다. 식량 생산과 인구증가는 서로 뗄 수 없는 유기적 관계를 맺고 있어서 어느 하나가 다른 하나로부터 급격하게 이탈하는 것은 상상하기 어렵다. 이렇게 시계열 자료가 중장기적으로 서로 종속적인 관계를 맺는 것을 오늘날의 통계학 용어로 공적분(cointegrated)이라고 부른다(Engle and Granger 1987). 주식가격과 그와 연동된 선물 상품의 가격이나 소비지출과 소득의 관계가 공적분 관계의 대표적인 예이다. 식량 생산과 인구증가는 장기적으로 공적분의 관계에 있음을 쉽게 짐작할 수 있다. 인구증가가 식량 생산을 압도하면 식료품의 가격이 상승하여 식량 생산방법의 개선에 대한 경제적 유인이 증가할 것이며 식료품 가격이 상승하면 자녀양육에 대한 비용이 증가하므로 출산에 대한 유인이 감소하여 인구증가를 억제할 것이다. 이런 이유로 이 두 변수는 국지적인 이탈 외에 파국적인 이탈이 나타날 가능성은 매우 낮다.
21세기 사회과학자의 관점에서 놀랍고 안타까운 점은 맬더스가 자신이 당대까지 수집된 자료를 통해 찾은 패턴을 결정론적 사회법칙으로 확신하고 이에 기반하여 미래를 예측했다는 점이다. 산업화가 진행되고 자본주의가 발전하면서 인구증가가 둔화될 가능성, 농업생산이 혁명적으로 개선될 수 있는 가능성, 그리고 식량 생산과 인구증가가 경제적 유인과 제도로 서로 상호 연관되어 있을 가능성을 보지 못한 채, 미래를 과거의 단순한 연장으로 보았던 것이다.
맬더스의 결정론적 사회 법칙은 논리적으로도, 경험적으로도, 역사적으로도 상당한 오류를 드러냈음에도 불구하고 당대 빈민정책의 형성 과정에 지대한 영향을 주었고 1832년과 1834년의 구빈법 개혁의 이론적 토대가 되었다. 바로 이 점이 사회공학이 경험적 사회과학의 산파가 될 수는 있지만 사회과학을 대체할 수는 없는 이유이다.
p.51~52
자료를 어떤 형태로 기록하고 연구자가 구상하는 특징을 어떻게 자료를 통해 측정할 것인가의 문제는 매우 복잡하고 어려운 문제이다. 예를 들어 국가 간의 전쟁을 0과 1이라는 이분형 자료로 간주하고 그 발생연도를 기록한다는 것은, 국가 간의 전쟁이 그 원인과 결과, 전개 과정의 차이에도 불구하고 어떤 공통점(예: 국가 간의 갈등이 전쟁으로 비화하느냐 아니면 협상과 대화에 의해 회피되느냐)이 존재한다고 가정하는 것이다. 반면 전쟁이 갖는 이질성에 주목한다면 위와 같은 이분형 자료로의 정리는 지나친 단순화이다. 내전과 국가 간 전쟁을 나누고 전쟁 진행방식의 종류를 전면전, 국지전, 게릴라전 등으로 세분화해야 하며, 전쟁 참여 국가의 수, 사상자 수, 민간인 피해 정도, 전쟁의 지속 시간, 전쟁 수행 방식 등을 더 세분화해서 기록해야 할 것이다.
p.54~55
원인이란 연구질문에서 연구대상에 작용을 가하는 가장 근원적인 변수이며 결과란 원인에 의해 영향받는 변수이다. 원인과 결과를 지나치게 가깝게 정하면 동어반복이 되어 과학적으로 가치가 없는 연구가 되기 쉽다. 예를 들어 제노사이드(genocide)가 일어나는 원인이 무엇인가를 설명하기 위해 그 원인을 전쟁에서 찾는다면 거의 모든 제노사이드가 전쟁에서 발생하기 때문에 사실상 동어 반복이 된다. 보다 나은 질문은 제노사이드가 일어나는 전쟁의 특징은 무엇인가? 또는 전쟁이 어떤 경우에 제노사이드를 야기하는가?와 같은 형태가 되어야 할 것이다. 반대로 원인을 너무 멀리서 찾는 것도 과학적 가치가 취약한 연구가 될 수 있다. 예를 들어 제노사이드의 원인을 인간의 사악한 본성에서 찾는다면 그 사이에 존재하는 수많은 다른 요인들의 복잡한 효과(상쇄효과 또는 확증효과)를 확인하기 어려워, 사실상 검증 불가능한 질문이 될 것이다.
p.56
추론의 방향에 따라 인과적 추론은 다음 두 가지로 구분될 수 있다(Dawid, 2000). 실업율의 변화와 민주당 하원의원 후보들의 평균 득표율 간의 인과적 관계를 연구한다고 가정하면, 다음 두 가지의 인과적 추론을 생각해볼 수 있다.
- 인과효과 측정(estimation of effects of causes): X(실업율의 변화)의 Y(민주당 하원의원 후보들의 평균 득표율)에 대한 인과적 효과를 측정하는 것으로 이에 해당하는 연구질문의 예는 "다른 요인들의 영향을 모두 통제했을 때, 실업율의 변화는 민주당 하원의원 후보들의 평균 득표율에 어떤 영향을 주는가?"이다.
- 추적(investigation of causes of effects): Y(민주당 하원의원 후보들의 평균 득표율)의 변화에 대한 원인을 X(실업율의 변화)에 귀속시킬 수 있는지를 추적하는 것으로, 이에 해당하는 연구질문은 "이번 선거에서 민주당 하원의원 후보들의 득표율이 예상보다 매우 낮게 나왔다. 그 원인을 우리는 실업율의 증가에서 찾을 수 있을까?"가 될 수 있다.
경제학이나 공공정책에서 사용되는 프로그램 평가(program evaluation)는 인과효과 측정에 해당되고 역학(epidemiology)의 관찰적 연구는 추적에 해당된다.
p.56~58
기술과 설명을 거친 이론은 내적 타당성(internal validity)을 인정받았다고 볼 수 있다. 예를 들어, 교육에 대한 투자의 증가가 청소년의 일탈을 줄이는 효과를 설명하는 이론이 수립되었고 그 맥락과 과정이 관측자료를 통해 비교적 정확하게 확인되었다고 가정하자. 이제 연구자는
- "과연 이러한 발견이 다른 장소와 시간에서도 반복되어 재현할 수 있는가?"
- "현재의 청소년 일탈 수준을 절반 이상 줄이기 위해서는 교육에 대한 투자가 어느 정도나 증가해야 하는가?"
- "교육에 대한 투자의 증가가 청소년 일탈에 미치는 영향은 지속적으로 나타나는가 아니면 한계체감하는가?"
와 같은 외적 타당성(external validity)에 대한 질문에 맞닥뜨리게 된다. 기술을 통해 문제에 대해 정확한 이해를 한 뒤, 설명으로 그 인과적 과정을 분석하였다면, 이제 그 설명을 통해 얻게 된 분석의 결과가 실제 자료의 세계에서 타당성을 인정받을 수 있는지 살펴봐야 한다. 실제 세계에서 모형의 세계로 들어간 뒤, 다시 실제의 세계로 나오는 변증법적 과정이 사회과학 연구라면, 예측과 해석은 모형을 거쳐 새로운 세계에 도달하는 과정이라고 할 수 있다.
예측과 해석이 중요한 이유는 크게 세 가지로 나눠볼 수 있다. 먼저 관측자료에 대한 설명에만 지나치게 집중할 경우, 과적합(overfitting)의 문제가 발생할 수 있다. 즉 관측한 사건의 설명력을 높이기 위해 가능한 많은 조건들 또는 변수들을 나열할 경우 이미 일어난 사건의 설명에만 최적화된, 그러나 미래 혹은 미지의 사건들과는 매우 동떨어진 설명이 될 수 있다. 통계학에서 편차와 분산 사이에 상쇄관계가 존재한다는 점은 잘 알려진 사실이다. 마찬가지로 자료분석에서 내적 타당성과 외적 타당성 사이에도 상쇄관계가 존재한다. 실제 자료 생성 과정을 정확히 알지 못하는 한, 내적 타당성에 최적화된 연구는 외적 타당성에서 상당한 문제점을 노출할 수 있다.
예측과 해석이 중요한 두 번째 이유는 설명의 시간적 제한성 때문이다. 합리적 인간들은 과거의 규칙성을 학습한 후, 그에 대한 서로의 반응을 예측하고 이에 맞춰 행동할 것이다. 루카스(Robert Emerson Lucas Jr, 1937~) 비판으로 잘 알려진 거시경제 예측모형에 대한 비판은 이러한 시간적 제한성에 대한 다른 표현이라고 볼 수 있다. 주어진 조건(인플레이션 증가)에 대한 인간의 집단적 선택(실업의 감소)에 대한 설명은 시간적 지평(미래 인플레이션 수준에 대한 경제행위자들의 에측)에 의해 제약될 수밖에 없다는 것이다. 과거의 사건이 미래에도 동일하게 전개될 것이라는 설명은 대부분 인간의 예측이 개입되는 시간적 지평을 도외시한 경우가 많다.
예측과 해석이 중요한 세 번째 이유는 사회과학적 설명은 결정론적일 수 없기 때문이다. 미래 혹은 미지의 실제 자료는 다양한 연관효과와 상호작용을 동반하여 생성된 것이고 이는 모형의 세계에서 구축된 가상의 자료와 다를 수밖에 없다. 모형의 세계에서 구축된 가상의 자료는 모형 내 불확실성(within model uncertainty)만을 반영한 것이라면 실제 세계에서 관측된 자료는 근본적 불확실성(fundamental uncertainty)을 포함하기 때문이다. 추정된 모수가 가진 표집분포(sampling distribution)가 모형 내 불확실성의 예이다. 모형 내 불확실성은 우리가 이미 알고 있는 불확실성(known unknown)인 반면 근본적 불확실성은 우리가 알 수 없는 불확실성(unknown unknowns)이다.
p.59
사회과학 자료분석의 원칙
- 자료의 양(quantity)보다 질(quality)을,
- 연구 방법(research method)보다는 연구 설계(research design)의 중요성을
- 성급한 일반화보다는 맥락의 중요성을
- 자료생성 규칙(data generating process)에 대한 이해의 중요성을
그리고 마지막으로
- 모든 상관성이 인과성이 아니라는 점을 항상 명심하는 것이다.
p.64
확률을 추상적 개념이나 주관적 믿음이 아니라 객관적 실재로 보는 시각은 당대를 지배하고 있던 뉴튼주의적 세계관의 반영이라고 볼 수 있다. 뉴튼주의적 결정론적 세계관과 확률에 대한 객관적 실재론은 하나의 맞쌍을 이루며 확률이론 발전에 중요한 족적을 남기게 된다.
p.64~66
1770~80년에 이르는 동안 라플라스의 주된 관심은 사건의 발생을 설명하는 법칙을 설명하려면 오차(error)에 대한 정확한 설명이 필요하다는 것이었다. 만약 관측자료가 고정값과 오차에 의해 생성된 것이라면,
관측자료 = 고정값 + 오차.
따라서 관측자료에서 오차를 제거하면 우리가 알지 못하는 고정값을 계산할 수 있다.
즉, 고정값 = 관측자료 - 오차
이것이 라플라스의 관심사였다. 따라서 라플라스에게 확률이론은 오차의 학문이었다. 라플라스가 베이즈의 원고를 읽었거나 알고 있었는지는 분명하지 않으나 라플라스는 자신만의 방식으로 베이즈와 같은 결론에 도달한다. 우리가 알지 못하는 고정값(theta)은 그것에 확률을 부여함으로써(p(theta)) 유추할 수 있다는 것이다. 우리가 관측한 자료를 D라고 하고 우리가 알고자 하는 확률값을 theta라고 하면, 라플라스는 다음과 같은 확률의 전복(inversion)을 통해 확률값에 대한 정보를 얻을 수 있다고 보았다.
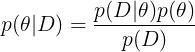
이러한 전복을 통해 라플라스는 베르누이(Jacob Bernoulli, 1655~1705)로부터 시작된 이항확률(binomial probability)에 대한 확률적 접근을 통계적 추론(statistical inference)으로 한 단계 발전시키는 역사적인 기여를 할 수 있었다. 기지의 정보로부터 미지의 정보를 얻어내는 것이 추론이라면 확률이론을 체계적으로 이용하여 주어진 자료에서 미지의 정보(이항분포의 확률)를 체계적으로 도출하는 방법이 등장한 것이다. 이것이 바로 근대적인 의미의 통계적 추론의 시작점이었다.
그러나 그 못지 않게 중요한 발견은 바로 미지의 확률값을 실재하는 고정값으로 본 것이 아니라 확률분포를 따르는 임의변수(p(theta|D))로 가정했다는 점이다. 이러한 관점은 훗날 확률에 대한 주관적 해석으로 이어졌다. 확률에 대한 주관적 해석은 확률이 객관적으로 실재하는 것이 아니라 위험(risk)와 같은 주관적 믿음이라고 간주한다. 그러나 주관/객관의 대립보다 더 중요한 점은 바로 미지의 확률값을 고정된 것이 아니라고 봄으로써 결정론적 세계관에서 벗어날 수 있는 중요한 도약점이 탄생했다는 것이다.
즉 사회현상이 하나의 객관적 법칙과 확률론적 오차에 의해 발생되는 것이 아니라 우리가 결정론적이라고 믿는 법칙 자체가 사실은 확률론적 세계 안에 있다는 것이다. 이는 뉴튼주의적 세계관이나 신은 주사위를 던지지 않는다("God does not play dice.")고 믿었던 아인슈타인의 세계관을 넘어서서 하이젠베르크의 불확정성의 원리에 기반한 양자역학적 세계관과 맥을 같이한다고 볼 수 있다. 그리고 이러한 라플라스에 의한 확률의 전복은 오늘날 베이지안 통계학(Bayesian statistics)에 와서 완성된 형태를 취하게 된다.
'Growth > 통계' 카테고리의 다른 글
| 사례분석으로 배우는 데이터 시각화 (1) | 2023.10.19 |
|---|---|
| A/B 테스트 - 신뢰할 수 있는 온라인 종합 대조 실험 (0) | 2023.10.13 |
| 불멸의 이론 (2) | 2023.08.19 |
| 의료인을 위한 R생존분석 (0) | 2023.08.10 |
| 행동 데이터 분석 (0) | 2023.06.20 |



댓글