
1.
개론을 듣고 있다. 데이터 처리의 흐름이 어떻게 흘러가는지 전체적인 흐름 속에서
NoSQL은 어떻게 작동하는지 개론을 듣고 있다.
셔플링, 맵리듀스 등의 단어를 듣고 있는데 아직은 잘 와닿지 않는다.
1) 정렬과 집계 = 셔플링, 맵리듀스
2) 과정 : 셔플링, 결과 : 맵리듀스
선생님이 이렇게 풀어서 설명해주셨다.
그나마 좀 낫다.
2. 데이터 수집의 종류
1) 웹 수집 vs Log 수집
2) 웹 수집 : .html, .xml, .json -> 서비스 정보
3) Log 수집 : .txt, .csv, etc -> 클라이언트의 정보
4) 웹 크롤링 vs 웹 스크래핑 -> 웹 크롤링이 더 큰 개념 (크롤링은 객체를 긁어와서 저장)
3. MR & Spark
1) 예측모델(제시모델) = 원시데이터 + MR(집계) + 수익성 + 시간
2) Spark : 저장소 안에서 (클라우드, HDFS) 전처리하는 것
4. 데이터 전처리 파일에서의 파일 형식 변환
1) .txt -> .csv -> .json
2) .csv -> .json
3) .xml -> .txt -> .csv, .json
4) .json
5) .sql -> .csv -> .json
5. Why Mongo?
1) 파일 형식 변환을 한 방에! 왔다갔다!
2) json도 무겁다! -> Bson(binary son) 으로
3) GEO 편함 (2D, 3D ...)
4) 분산처리
5) 문서화처리
6. Data Handling Process
1) 타 사이트 (Python) -> 수집(MongoDB) -> 시각화(Python)
2) 타 사이트 (Python) -> 수집(MongoDB) -> 적재(MR) -> 예측 분석(Spark) -> 시각화(Python)
3) Log 수집(.log, .txt) -> 적재(MR) -> 예측 분석() -> 시각화
ⓐ 소량일 경우 .log, .txt -> Hadoop -> Python으로
ⓑ 대량일 경우 .log, .txt ->MongoDB를 통해 .json으로 -> java -> Spark -> Python
4) 정형 DB (sql) -> 적재(MR) -> 시각화(Python)
7. MongoDB의 Log를 살펴보자!



1) MongoDB는 DBPath 하나 당 1개의 포트를 사용
2)
3) C 바로 밑에 있는 MongoDB vs Program Files 밑에 있는 MongoDB => 다르다.



cfg, dbpath, log파일 = 기본 설정 파일
8. MongoDB의 환경설정 셋팅
1)

2)



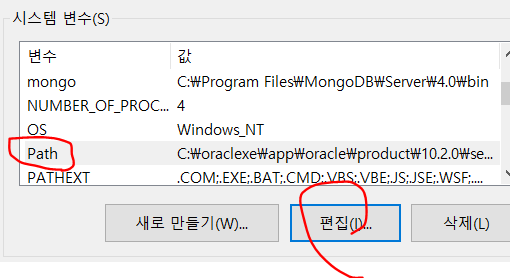

3) 전역변수로 지정해주었으므로 콘솔에서 어느 위치에서든 mongo -help를 입력하여 작동하는지 확인한다.




4) mongodb를 net stop mongodb라는 명령어를 통해서 중단시킬 수 있으나,
관리자 권한으로 cmd를 실행시켜야 한다. 그렇지 않으면 다음과 같은 오류가 발생한다.

5) 다음과 같이 디렉토리를 생성해 준 뒤


다음과 같이 파일을 생성해 준다.
6) 다음과 같이 입력해주면



이렇게 만들어준 뒤

서비스를 실행해 주면

다음과 같이 빈 폴더에 이것저것 생긴다.
7) Score 컬렉션의 갯수만 출력해보는 함수
ㅕㅓㅓ
8) Score의 이름만 출력하는 함수
db.Score.find({}, {name:1});
8. 이후 일정
월 : 몽고 설치 _ 빅데이터 흐름 / 회의_ 1차 프로젝트
화 : 몽고 sql _ 인덱스 / 2차 회의
수 : 인덱스 _ 파일 처리 / 조별 미팅 (회의 결과)
목 : 복제 _ 샤딩
금 : mongo_spring
'국비교육' 카테고리의 다른 글
| MongoDB 수업 3일차 (0) | 2019.04.17 |
|---|---|
| MongoDB 수업 2일차 - 쿼리 (0) | 2019.04.16 |
| 국비교육 76일차 (0) | 2019.03.26 |
| 국비교육 75일차 (0) | 2019.03.25 |
| 국비교육 74일차 (0) | 2019.03.22 |


댓글